


We’re thrilled to be partnered with Confluent today as they announce the general availability of the industry’s only cloud-native, serverless Apache Flink® service. Available directly within Confluent’s data streaming platform alongside a cloud-native service for Apache Kafka®, the new Flink offering is now ready for use on AWS, Azure, and Google Cloud. Directly integrated with Synthesis, Confluent provides a simple solution for accessing and processing data streams from across the entire business to build a real-time, contextual, and trustworthy knowledge base to fuel applications.
Easily build high-quality, reusable data streams with the industry’s only cloud-native, serverless Flink service
Apache Flink is a unified stream and batch-processing framework that has been a top-five Apache project for many years. Flink has a strong, diverse contributor community backed by companies like Alibaba and Apple. It powers stream processing platforms at many companies, including digital natives like Uber, Netflix, and Linkedin, as well as successful enterprises like ING, Goldman Sachs, and Comcast.
Fully integrated with Apache Kafka® on Confluent Cloud, Confluent’s new Flink service allows businesses to:
- Effortlessly filter, join and enrich your data streams with Flink, the de facto standard for stream processing
- Enable high-performance and efficient stream processing at any scale, without the complexities of infrastructure management
- Experience Kafka and Flink as a unified platform, with fully integrated monitoring, security, and governance
Confluent’s fully managed Flink service is now generally available across all three major cloud service providers, providing customers with a true multi-cloud solution and the flexibility to seamlessly deploy stream processing workloads everywhere their data and applications reside. Backed by a 99.99% uptime SLA, Confluent ensures reliable stream processing with support and services from the leading Kafka and Flink experts.
Getting Started
As Synthesis we have provided an easy way to illustrate how to get started as Data Engineer to develop and manage robust, scalable and resilient data streaming applications on Confluent’s fully managed Flink platform, providing a wide range of data analytics solutions to different clients with multiple use cases across various industries.
It is important for us to note that: Confluent Cloud for Apache Flink®️ is currently available for Preview. A Preview feature is a Confluent Cloud component that is being introduced to gain early feedback from developers. Preview features can be used for evaluation and non-production testing purposes or to provide feedback to Confluent.
Below is an easy step-by-step getting started with descriptive “How-To’s”.
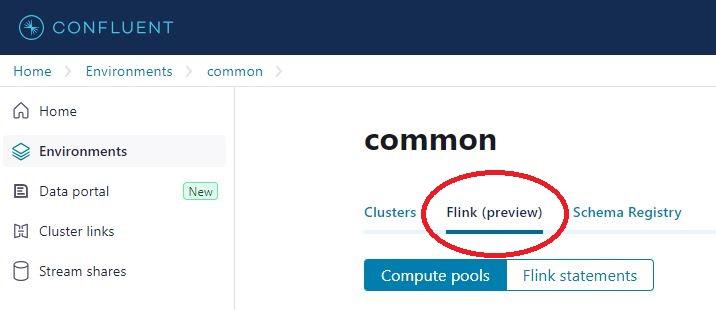
Step 1: Create a Flink compute pool
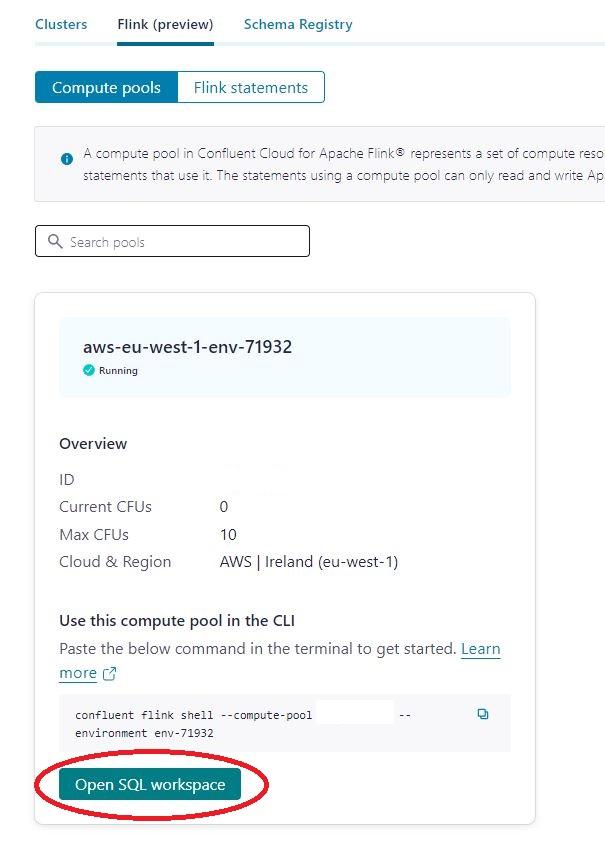
Inside your desired confluent environment, select the Flink tab:
Step 2: Create a workspace
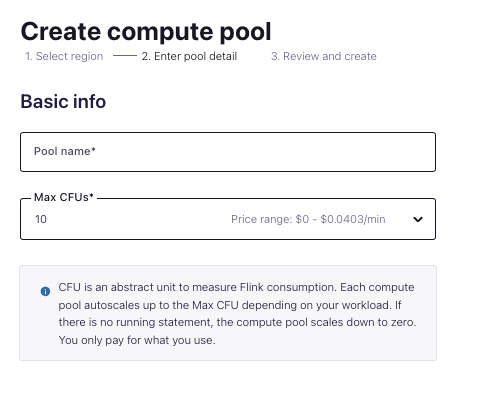
Once you clink create new compute pool, you will have to set the pool name, and configure the maximum CFUs required, also note the compute charges per min that come with this configuration as it has an impact on your billing.
Step 3: Run a SQL statement
Once you have your workspace created, click on the Open SQL workspace button to open the workspace with an SQL editor:
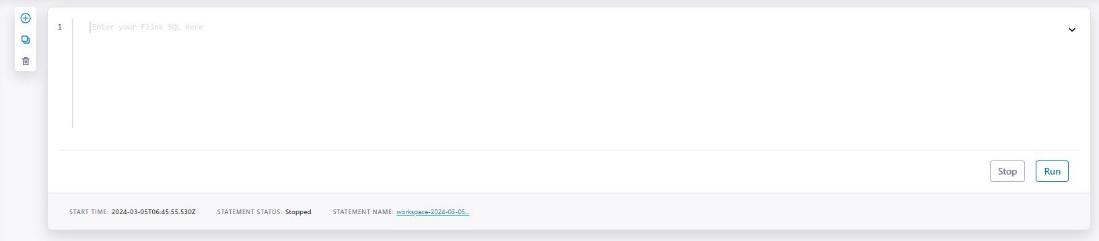
The editor should look similar to the image below with a Run and Stop button, these respectfully run and stop your FlinkSQL queries.
Step 4a: (Optional) Query existing topics
The CREATE TABLE can be used to create a table which will also create a corresponding topic.
An example of how to create a table and configure a few properties:
| CREATE TABLE user_data ( `id` BIGINT, `name` STRING, `age` INT, `created_at` TIMESTAMP_LTZ(3) ) WITH ( ‘kafka.cleanup-policy’ = ‘delete’, ‘kafka.retention.time’ = ‘86400000’ ); |
In this example, the WITH statement is used to configure the retention time and clean-up policy for the corresponding topic that was created.
Click here for documentation on more configurations that can be used with the WITH statement.
Like SQL, the INSERT statement can be used to insert data into a table.
An example of how to insert data into a table:
| INSERT INTO user_data VALUES (1234567890, ‘John Doe’, 24, CURRENT_TIMESTAMP); |
The SELECT statement allows for querying and filtering data inside a table or topic.
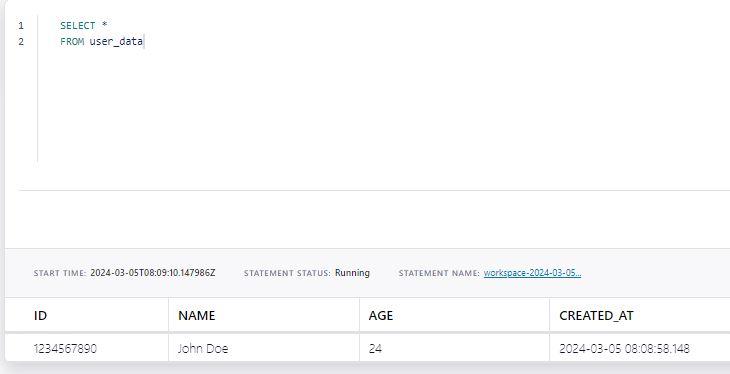
An example of how to query all the data inside a table or topic:
| SELECT *FROM user_data |
Output:
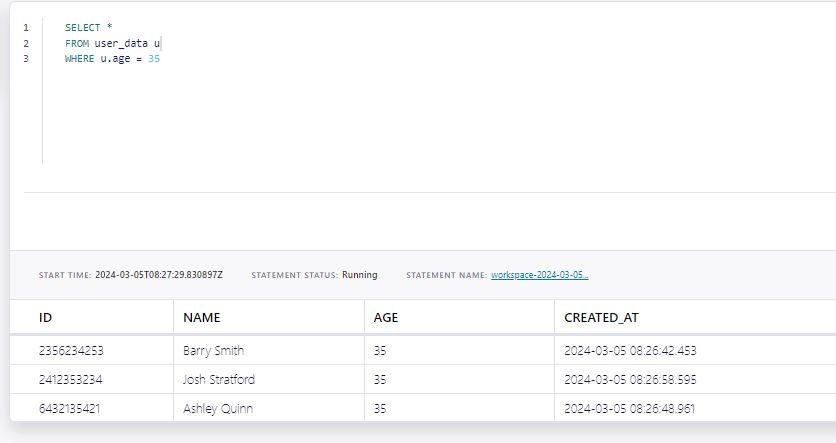
We can filter our results by using the WHERE statement.
An example of filtering users that are 35 years old:
| SELECT * FROM user_data u WHERE u.age = 35 |
Output:
Step 4b: (Optional) Using Sample Data
Here is an example of using mock telematics data for filtering, joining and windowing for the desired useful data.
There is a constant stream of vehicle events flowing into the topic vehicle_data and a stream of periodic location events flowing into the compacted topic location_data:
Both of these topics can be used to create several enriched streams of data for business use.
Example of vehicle_data event:
| { “id”: “081d2d60-8fe4-4319-b090-93ab2c56f8d6”, “car”: “Toyota Starlet”, “state”: “driving”, “speed”: 117.30, “speed_unit”: “km/h”, “road_name”: “B22 Highway”, “position_x”: -283.04, “position_y”: -144.08, “created_by”: 1709645218966 } |
Example of location_data event:
| { “name”: “B22 Highway”, “traffic”: “Very High”, “temperature”: 26.0, “temperature_unit”: “Degree Celsius”, “weather”: “Sunny” } |
For the vehicle_data, it will only be beneficial to the business once there is some analysis done by streaming the vehicle events and joining them to the location events which will enrich the data for meaningful analysis.
This is where the Flink application comes into play and jobs can scale up based on the underlying configuration done at the compute pool level. This then allows seamless scaling up and down to provide optimal performance without the intervention of a support engineer.
Vehicle and Location data can be joined on their common column:
| SELECT * FROM vehicle_data v INNER JOIN location_data l ON v.road_name = l.name |
We can apply filters to get only the useful information out of this stream, for instance, vehicles that are driving on high-traffic roads.
Here is an example of a filtered join:
| SELECT * FROM vehicle_data v INNER JOIN location_data l ON v.road_name = l.name WHERE v.state = ‘driving’ AND l.traffic = ‘Very High’ |
We can create a hopping window to identify each vehicle’s average speed. A hopping time window has a fixed duration and hops by a specified hop interval. In this case, we want the hopping window to overlap therefore we will set the hopping interval to smaller than the windowing duration.
Here is an example of a hopping window query:
| SELECT window_start, window_end, AVG(speed) AS average_speed FROM TABLE( HOP(TABLE vehicle_data, DESCRIPTOR(created_by), INTERVAL ‘1’ MINUTE, INTERVAL ‘2’ MINUTE ) ) GROUP BY id, window_start, window_end; |
The power of confluent cloud-managed Flink has a number of benefits that a Data Streaming engineer or team can leverage, and they are illustrated below.
